About
This repository contains an implementation of a JavaScript vector search algorithm, along with an analysis of its running times for different search space sizes. Allows for the searching/ranking of a list of javascript objects with "embedding" fields.
| Notes | Changelog | Test | Data |
|---|
Usage
Either clone this repository to your project or use
npm i embedding-search-node
In a new file...
//bring in functionalities you need
const {
GetRankedEmbeddingSearch,
smartVector,
EmbeddingInterface
} = require("embedding-search-node");
//initialize the embedding interface
const embeddingsInterface = new EmbeddingInterface(
"<Your Openai Api Key>", //required
"<Your openai org> ", //optional
);
//predict the cost of embedding some text
const exampleText = "Some random text to be embedded by the interface "
const { cost , tokens } = embeddingsInterface.predictCost(exampleText)
console.log(`Embedding Prediction:\n# Tokens: ${tokens}\nCost: $${cost.toFixed(4)}`)
//get the embedding of the text
const {embedding,error} = await embeddingsInterface.getEmbedding(exampleText);
//check for errors
if(error) return console.error(error)
//define some 'embeddedItems' or fetch from some database
const items = [...embeddedItems]
//optional some parameters to fine tune the search
let n = 20 //default result cap is 10 here we are upping that to 20
let threshold = 0.75 //only vectors with similarity to vector within threshold will be considered in the ranking
//use the example text as a query on the embeddedItems
const result = await GetRankedEmbeddingSearch(
items,
embedding,
threshold,
n
);
console.log(result)
Most if not all of the functions are documented with JSDoc as well!
Updates
v0.0.6 - 😬 Fixed the creation of 'smartVectors' which were ultimately a poor understanding of embeddings. They are already normalized so just compute the dot product instead dot products / |a|*|b| nonsense.
v0.0.5 - 🧬 Created a wrapper for the openai embedding api. Generates embeddings using the 'text-embedding-ada-002' model.
v0.0.5 - 💰 Implemented a function to estimate price & token count. Based on OpenAI's Pricing
v0.0.4 - ❌ Removed the "anomaly" feature on vector search as it seemed out of scope for the ranking function.
v0.0.4 - ✨ Refactored the return value of the search results array, to include context from the original array instead of the old [score,index] format
v0.0.3 - 💪 Max size of vector space increased to 160,300 vectors of length 1536. (Roughly 7% increase)
v0.0.3 - 👨🏻💻 Changed implementation to use a maxheap for search spaces of sizes > 20,000 , opting for simple array and builtin sort for smaller spaces.
v0.0.3 - 🚀 Implemented a "smartVector" data structure that stores a vector along with its magnitude. This dramatically improved the performance of the cosineSimilarity function by preventing recalculation of magnitude for the query vector. The trade off is a slightly longer time to create a new vector, but seems worthwhile for the search improvements
v0.0.2 - 🚮 Switched to using a maxheap for larger inputs. Introduced a threshold parameter to avoid sorting clearly irrelevant embeddings. Lots of time spent in computation of magnitude.
v0.0.1 - ⚖️ A max capacity of 150,000 vectors of length 1536 established.
v0.0.1 - 💩 A basic implementation of calculating cosine similarity to search a vector space. Utilized mergesort.
Notes
Avoiding senseless sorting
Previously, every comparison result was stored to be sorted, however by incorporating a "threshold" parameter, we can omit clearly irrelevant results from being included in the list to be sorted. For n < 20,000 items, the builtin javascript sort function proved performant enough.
Maxheap for large n
for search spaces with more than 20,000 items, a maxheap is utilized. Introducing parameter "m" as the max number of results, instead of sorting through all "n" items, we simply perform "m" heap extractions.
Performance gains with "smart vectors"
In the prior implementation, magnitudes of vectors were recomputed each time a vector comparison was performed. In order to optimize this, I implemented a "smartVector" function that takes a regular number[] and converts it into an object with the format
{
v: number[] //the original vector array
m: number // the magnitude of the vector
}
By computing the magnitude of the vector at creation, we save the comparison function from 2n calls to magnitude (previously each comparison performed 2 calls to magnitude for each of the n vectors).
Experiment
This experiment aimed to assess the performance of a vector comparison and ranking function that utilizes cosine similarity for determining the similarity between embedding vectors. The function was evaluated on various search space sizes, ranging from 10 to 163,000 items. Average execution times were measured for each search space size, and the distribution of computation time between vector comparisons and the merge sort step was analyzed. Currently the maximum searchable vectors in one call of the function is 163000 vectors of length 1536 ( without running out of memory and the process crashing ).
The experiement was run on my 2020 M1 Macbook Air, using Node v19.8.1
Data
The provided data includes average running times (in milliseconds) for the algorithm's execution on various search space sizes. The collected data points are as follows:
| Search Space | Running Time (ms) |
|---|---|
| 10 | 0.026 |
| 100 | 0.185 |
| 1000 | 2.610 |
| 2500 | 6.108 |
| 5000 | 12.216 |
| 10000 | 23.942 |
| 25000 | 52.884 |
| 30000 | 67.020 |
| 40000 | 192.223 |
| 50000 | 126.527 |
| 80000 | 160.684 |
| 130000 | 284.091 |
| 163000 | 344.077 |
Running Time v0.0.3 - v0.0.5
Running Time(ms) over search space size (n). Improvements include implementation of "smartVector" format to reduce calls to expensive "magnitude" function. For small n (n ≤ 20000), use builtin sort to prevent heap overhead.
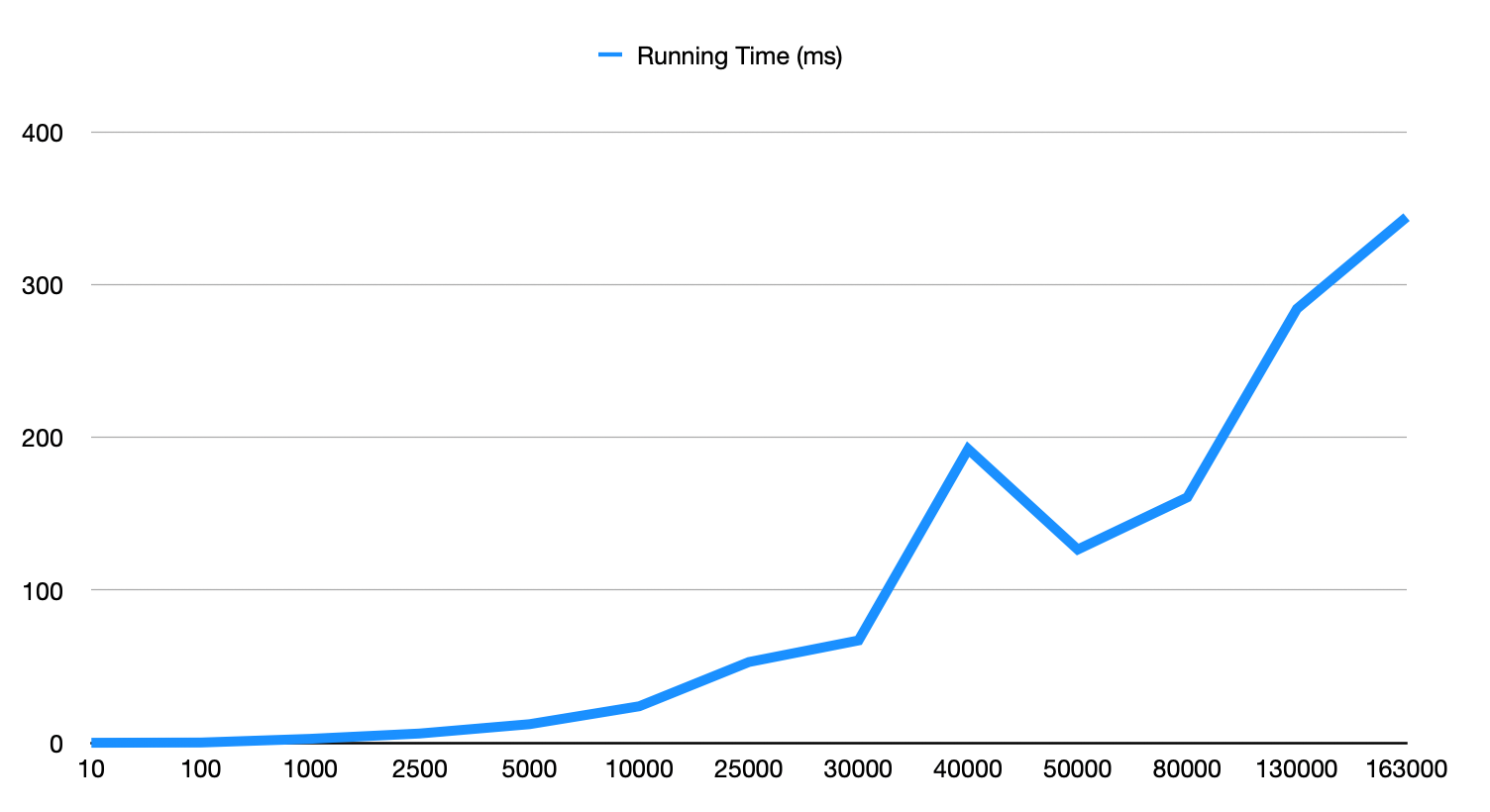
- v0.0.1 and v0.0.2 took almost 800ms compared to the new version (v0.0.3+) taking an average of around 350ms for the same (n=150,000) test size.
- Further optimizations may result in support for even larger search space sizes.
Insights
- Variability: Some data points deviate from the overall increasing trend, indicating that factors other than search space alone can influence the algorithm's performance. This can likely be attributed to the fact that the sorting step is determined by the number of "over threshold" similarity elements included in the search space.
This library is a rough work in progress. Mostly just experimental but you are welcome to use it in any of your software, please be sure to leave feedback on what features you would find useful to add, or any general suggestions for improvements.