pdf-template-parse 


A JavaScript frontend cross-browser compatible 'PDF parser w/ template engine' to convert pdf documents into organized data objects.
Live Demo: Click Here
Install
Install with npm:
npm install pdf-template-parseInstall with yarn:
yarn add pdf-template-parseIntroduction
This module exposes two functions:
1 - pdfParse (character & location extraction)
;pdfParse takes a pdf file and returns a promise. Promise resolves all the character data (character code, text, x, y, width) found in the provided document allowing the user to process the raw data themselves.
2 - pdfTemplateParse (character extraction & templating)
;pdfTemplateParse takes a pdf file and a template file and returns a promise. Promise resolves all the values / tables declared in the template file. (see example below for sample template file)
Example Usage
Example 1: helloWorldDemo.pdf
sample pdf download: helloWorldDemo.pdf
;; const characterData = ;console;Output: (console screenshot)

** Note: the promise will not resolve if the browser tab is not visible.
Example 2: helloWorldDemo.pdf w/ template file
Template file: helloWorldDemo.json
Code:
;;; const data = ;console;Output: (console screenshot)
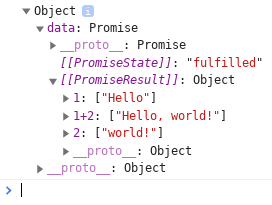
** Note: the promise will not resolve if the browser tab is not visible.
Todo
- Add tests
- Replace char_offset option with character map detection
- Add value validation.
- Add template validation.
- Add node support (either remove canvas dependency or add node canvas package)
Authors
- Thomas J. Herzog - https://github.com/tomrule007
License 📄
This project is licensed under the MIT License - see the LICENSE file for details